publications
2025
 PuzzleGPT: Emulating Human Puzzle-Solving Ability for Time and Location Prediction Hammad Ayyubi, Xuande Feng, Junzhang Liu, Xudong Lin, Zhecan Wang, and Shih-Fu Chang NAACL Findings 2025 [Abs] [HTML]
PuzzleGPT: Emulating Human Puzzle-Solving Ability for Time and Location Prediction Hammad Ayyubi, Xuande Feng, Junzhang Liu, Xudong Lin, Zhecan Wang, and Shih-Fu Chang NAACL Findings 2025 [Abs] [HTML]The task of predicting time and location from images is challenging and requires complex human-like puzzle-solving ability over different clues. In this work, we formalize this ability into core skills and implement them using different modules in an expert pipeline called PuzzleGPT. PuzzleGPT consists of a perceiver to identify visual clues, a reasoner to deduce prediction candidates, a combiner to combinatorially combine information from different clues, a web retriever to get external knowledge if the task can’t be solved locally, and a noise filter for robustness. This results in a zero-shot, interpretable, and robust approach that records state-of-the-art performance on two datasets – TARA and WikiTilo. PuzzleGPT outperforms large VLMs such as BLIP-2, InstructBLIP, LLaVA, and even GPT-4V, as well as automatically generated reasoning pipelines like VisProg, by at least 32% and 38%, respectively. It even rivals or surpasses finetuned models.
 DELOC: Document Element Localizer Hammad Ayyubi, Puneet Mathur, Mehrab Tanjim, and Vlad I Morariu EMNLP 2025 [Abs] [HTML]
DELOC: Document Element Localizer Hammad Ayyubi, Puneet Mathur, Mehrab Tanjim, and Vlad I Morariu EMNLP 2025 [Abs] [HTML]Editing documents and PDFs using natural language instructions is desirable for many reasons – ease of use, increasing accessibility to non-technical users, and for creativity. To do this automatically, a system needs to first understand the user’s intent and convert this to an executable plan or command, and then the system needs to identify or localize the elements that the user desires to edit. While there exist methods that can accomplish these tasks, a major bottleneck in these systems is the inability to ground the spatial edit location effectively. We address this gap through our proposed system, DELOC (Document Element LOCalizer). DELOC adapts the grounding capabilities of existing Multimodal Large Language Model (MLLM) from natural images to PDFs. This adaptation involves two novel contributions: 1) synthetically generating PDF-grounding instruction tuning data from partially annotated datasets; and 2) synthetic data cleaning via Code-NLI, an NLI-inspired process to clean data using generated Python code. The effectiveness of DELOC is apparent in the >3x zero-shot improvement it achieves over the next best Multimodal LLM, GPT-4o.
2024
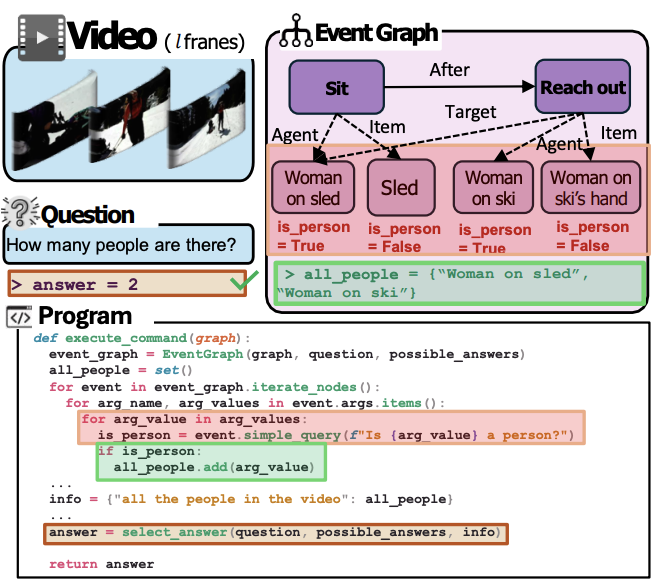 ENTER: Event Based Interpretable Reasoning for VideoQA Hammad Ayyubi, Junzhang Liu, Ali Asgarov, Zaber Ibn Abdul Hakim, Najibul Haque Sarker, Zhecan Wang, Chia-Wei Tang, Hani Alomari, Md. Atabuzzaman, Xudong Lin, Naveen Reddy Dyava, Shih-Fu Chang, and Chris Thomas NeurIPS MAR Workshop 2024 [Abs] [HTML]
ENTER: Event Based Interpretable Reasoning for VideoQA Hammad Ayyubi, Junzhang Liu, Ali Asgarov, Zaber Ibn Abdul Hakim, Najibul Haque Sarker, Zhecan Wang, Chia-Wei Tang, Hani Alomari, Md. Atabuzzaman, Xudong Lin, Naveen Reddy Dyava, Shih-Fu Chang, and Chris Thomas NeurIPS MAR Workshop 2024 [Abs] [HTML]In this paper, we present ENTER, an interpretable Video Question Answering (VideoQA) system based on event graphs. Event graphs convert videos into graphical representations, where video events form the nodes and event-event relationships (temporal/causal/hierarchical) form the edges. This structured representation offers many benefits: 1) Interpretable VideoQA via generated code that parses event-graph; 2) Incorporation of contextual visual information in the reasoning process (code generation) via event graphs; 3) Robust VideoQA via Hierarchical Iterative Update of the event graphs. Existing interpretable VideoQA systems are often top-down, disregarding low-level visual information in the reasoning plan generation, and are brittle. While bottom-up approaches produce responses from visual data, they lack interpretability. Experimental results on NExT-QA, IntentQA, and EgoSchema demonstrate that not only does our method outperform existing top-down approaches while obtaining competitive performance against bottom-up approaches, but more importantly, offers superior interpretability and explainability in the reasoning process.
 JourneyBench: A Challenging One-Stop Vision-Language Understanding Benchmark of Generated Images Zhecan Wang, Junzhang Liu, Chia-Wei Tang, Hani Alomari, Anushka Sivakumar, Rui Sun, Wenhao Li, Md Atabuzzaman, Hammad Ayyubi, Haoxuan You, Alvi Ishmam, Kai-Wei Chang, Shih-Fu Chang, and Chris Thomas NeurIPS 2024 [Abs] [HTML]
JourneyBench: A Challenging One-Stop Vision-Language Understanding Benchmark of Generated Images Zhecan Wang, Junzhang Liu, Chia-Wei Tang, Hani Alomari, Anushka Sivakumar, Rui Sun, Wenhao Li, Md Atabuzzaman, Hammad Ayyubi, Haoxuan You, Alvi Ishmam, Kai-Wei Chang, Shih-Fu Chang, and Chris Thomas NeurIPS 2024 [Abs] [HTML]Existing vision-language understanding benchmarks largely consist of images of objects in their usual contexts. As a consequence, recent multimodal large language models can perform well with only a shallow visual understanding by relying on background language biases. Thus, strong performance on these benchmarks does not necessarily correlate with strong visual understanding. In this paper, we release JourneyBench, a comprehensive human-annotated benchmark of generated images designed to assess the model’s fine-grained multimodal reasoning abilities across five tasks: complementary multimodal chain of thought, multi-image VQA, imaginary image captioning, VQA with hallucination triggers, and fine-grained retrieval with sample-specific distractors. Unlike existing benchmarks, JourneyBench explicitly requires fine-grained multimodal reasoning in unusual imaginary scenarios where language bias and holistic image gist are insufficient. We benchmark state-of-the-art models on JourneyBench and analyze performance along a number of fine-grained dimensions. Results across all five tasks show that JourneyBench is exceptionally challenging for even the best models, indicating that models’ visual reasoning abilities are not as strong as they first appear. We discuss the implications of our findings and propose avenues for further research.
 Video Summarization: Towards Entity-Aware Captions Hammad A. Ayyubi, Tianqi Liu, Arsha Nagrani, Xudong Lin, Mingda Zhang, Anurag Arnab, Feng Han, Yukun Zhu, Jialu Liu, and Shih-Fu Chang EMNLP 2024 [Abs] [HTML]
Video Summarization: Towards Entity-Aware Captions Hammad A. Ayyubi, Tianqi Liu, Arsha Nagrani, Xudong Lin, Mingda Zhang, Anurag Arnab, Feng Han, Yukun Zhu, Jialu Liu, and Shih-Fu Chang EMNLP 2024 [Abs] [HTML]Existing popular video captioning benchmarks and models deal with generic captions devoid of specific person, place or organization named entities. In contrast, news videos present a challenging setting where the caption requires such named entities for meaningful summarization. As such, we propose the task of summarizing news video directly to entity-aware captions. We also release a large-scale dataset, VIEWS (VIdeo NEWS), to support research on this task. Further, we propose a method that augments visual information from videos with context retrieved from external world knowledge to generate entity-aware captions. We demonstrate the effectiveness of our approach on three video captioning models. We also show that our approach generalizes to existing news image captions dataset. With all the extensive experiments and insights, we believe we establish a solid basis for future research on this challenging task.
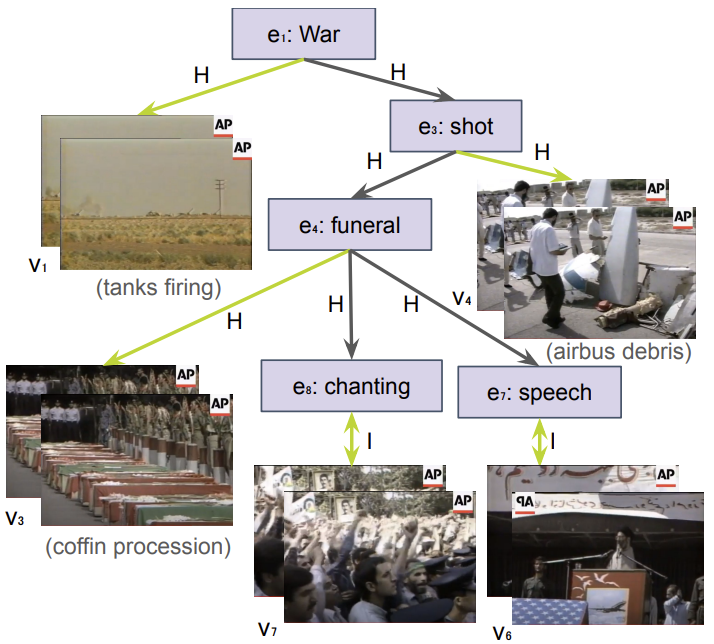 Beyond Grounding: Extracting Fine-Grained Event Hierarchies across Modalities Hammad A. Ayyubi, Christopher Thomas, Lovish Chum, Rahul Lokesh, Long Chen, Yulei Niu, Xudong Lin, Xuande Feng, Jaywon Koo, Sounak Ray, and Shih-Fu Chang AAAI 2024 [Abs] [HTML]
Beyond Grounding: Extracting Fine-Grained Event Hierarchies across Modalities Hammad A. Ayyubi, Christopher Thomas, Lovish Chum, Rahul Lokesh, Long Chen, Yulei Niu, Xudong Lin, Xuande Feng, Jaywon Koo, Sounak Ray, and Shih-Fu Chang AAAI 2024 [Abs] [HTML]Events describe happenings in our world that are of importance. Naturally, understanding events mentioned in multimedia content and how they are related forms an important way of comprehending our world. Existing literature can infer if events across textual and visual (video) domains are identical (via grounding) and thus, on the same semantic level. However, grounding fails to capture the intricate cross-event relations that exist due to the same events being referred to on many semantic levels. For example, the abstract event of "war” manifests at a lower semantic level through subevents "tanks firing” (in video) and airplane "shot” (in text), leading to a hierarchical, multimodal relationship between the events. In this paper, we propose the task of extracting event hierarchies from multimodal (video and text) data to capture how the same event manifests itself in different modalities at different semantic levels. This reveals the structure of events and is critical to understanding them. To support research on this task, we introduce the Multimodal Hierarchical Events (MultiHiEve) dataset. Unlike prior video-language datasets, MultiHiEve is composed of news video-article pairs, which makes it rich in event hierarchies. We densely annotate a part of the dataset to construct the test benchmark. We show the limitations of state-of-the-art unimodal and multimodal baselines on this task. Further, we address these limitations via a new weakly supervised model, leveraging only unannotated video-article pairs from MultiHiEve. We perform a thorough evaluation of our proposed method which demonstrates improved performance on this task and highlight opportunities for future research. Data: https://github.com/hayyubi/multihieve
 Detecting Multimodal Situations with Insufficient Context and Abstaining from Baseless Predictions Junzhang Liu, Zhecan Wang, Hammad Ayyubi, Haoxuan You, Chris Thomas, Rui Sun, Shih-Fu Chang, and Kai-Wei Chang ACM MM 2024 [Abs] [HTML]
Detecting Multimodal Situations with Insufficient Context and Abstaining from Baseless Predictions Junzhang Liu, Zhecan Wang, Hammad Ayyubi, Haoxuan You, Chris Thomas, Rui Sun, Shih-Fu Chang, and Kai-Wei Chang ACM MM 2024 [Abs] [HTML]Despite the widespread adoption of Vision-Language Understanding (VLU) benchmarks such as VQA v2, OKVQA, A-OKVQA, GQA, VCR, SWAG, and VisualCOMET, our analysis reveals a pervasive issue affecting their integrity: these benchmarks contain samples where answers rely on assumptions unsupported by the provided context. Training models on such data foster biased learning and hallucinations as models tend to make similar unwarranted assumptions. To address this issue, we collect contextual data for each sample whenever available and train a context selection module to facilitate evidence-based model predictions. Strong improvements across multiple benchmarks demonstrate the effectiveness of our approach. Further, we develop a general-purpose Context-AwaRe Abstention (CARA) detector to identify samples lacking sufficient context and enhance model accuracy by abstaining from responding if the required context is absent. CARA exhibits generalization to new benchmarks it wasn’t trained on, underscoring its utility for future VLU benchmarks in detecting or cleaning samples with inadequate context. Finally, we curate a Context Ambiguity and Sufficiency Evaluation (CASE) set to benchmark the performance of insufficient context detectors. Overall, our work represents a significant advancement in ensuring that vision-language models generate trustworthy and evidence-based outputs in complex real-world scenarios.
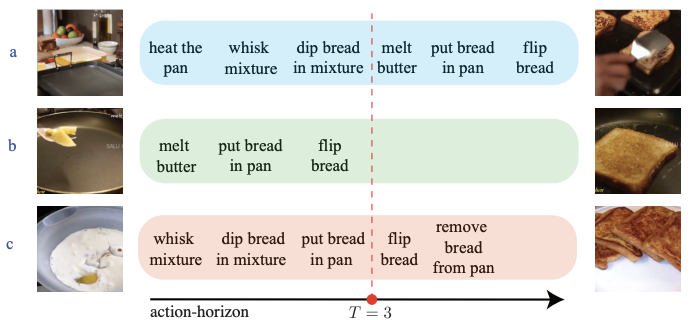 RAP: Retrieval-Augmented Planner for Adaptive Procedure Planning in Instructional Videos Ali Zare, Yulei Niu, Hammad Ayyubi, and Shih-Fu Chang ECCV 2024 [Abs] [HTML]
RAP: Retrieval-Augmented Planner for Adaptive Procedure Planning in Instructional Videos Ali Zare, Yulei Niu, Hammad Ayyubi, and Shih-Fu Chang ECCV 2024 [Abs] [HTML]Procedure Planning in instructional videos entails generating a sequence of action steps based on visual observations of the initial and target states. Despite the rapid progress in this task, there remain several critical challenges to be solved: (1) Adaptive procedures: Prior works hold an unrealistic assumption that the number of action steps is known and fixed, leading to non-generalizable models in real-world scenarios where the sequence length varies. (2) Temporal relation: Understanding the step temporal relation knowledge is essential in producing reasonable and executable plans. (3) Annotation cost: Annotating instructional videos with step-level labels (i.e., timestamp) or sequence-level labels (i.e., action category) is demanding and labor-intensive, limiting its generalizability to large-scale datasets.In this work, we propose a new and practical setting, called adaptive procedure planning in instructional videos, where the procedure length is not fixed or pre-determined. To address these challenges we introduce Retrieval-Augmented Planner (RAP) model. Specifically, for adaptive procedures, RAP adaptively determines the conclusion of actions using an auto-regressive model architecture. For temporal relation, RAP establishes an external memory module to explicitly retrieve the most relevant state-action pairs from the training videos and revises the generated procedures. To tackle high annotation cost, RAP utilizes a weakly-supervised learning manner to expand the training dataset to other task-relevant, unannotated videos by generating pseudo labels for action steps. Experiments on CrossTask and COIN benchmarks show the superiority of RAP over traditional fixed-length models, establishing it as a strong baseline solution for adaptive procedure planning.
2023
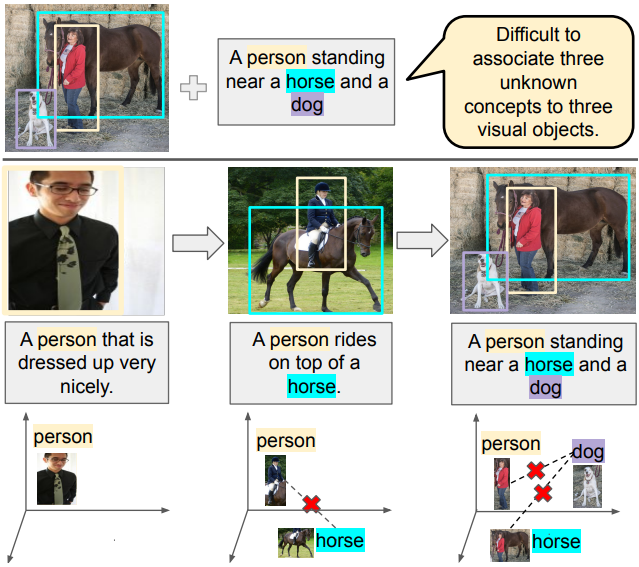 Learning from Children: Improving Image-Caption Pretraining via Curriculum Hammad A. Ayyubi, Rahul Lokesh, Alireza Zareian, Bo Wu, and Shih-Fu Chang ACL Findings 2023 [Abs] [HTML]
Learning from Children: Improving Image-Caption Pretraining via Curriculum Hammad A. Ayyubi, Rahul Lokesh, Alireza Zareian, Bo Wu, and Shih-Fu Chang ACL Findings 2023 [Abs] [HTML]Image-caption pretraining has been quite successfully used for downstream vision tasks like zero-shot image classification and object detection. However, image-caption pretraining is still a hard problem – it requires multiple concepts (nouns) from captions to be aligned to several objects in images. To tackle this problem, we go to the roots – the best learner, children. We take inspiration from cognitive science studies dealing with children’s language learning to propose a curriculum learning framework. The learning begins with easy-to-align image caption pairs containing one concept per caption. The difficulty is progressively increased with each new phase by adding one more concept per caption. Correspondingly, the knowledge acquired in each learning phase is utilized in subsequent phases to effectively constrain the learning problem to aligning one new concept-object pair in each phase. We show that this learning strategy improves over vanilla image-caption training in various settings – pretraining from scratch, using a pretrained image or/and pretrained text encoder, low data regime etc.
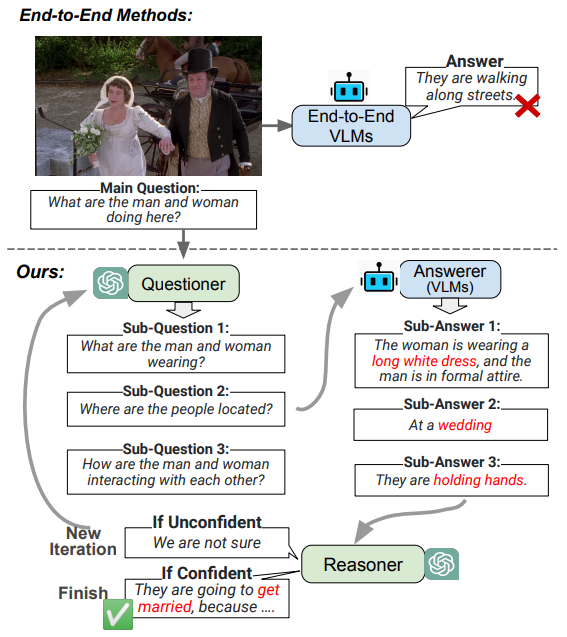 IdealGPT: Iteratively Decomposing Vision and Language Reasoning via Large Language Models Haoxuan You, Rui Sun, Zhecan Wang, Long Chen, Gengyu Wang, Hammad A. Ayyubi, Kai-Wei Chang, and Shih-Fu Chang EMNLP Findings 2023 [Abs] [HTML]
IdealGPT: Iteratively Decomposing Vision and Language Reasoning via Large Language Models Haoxuan You, Rui Sun, Zhecan Wang, Long Chen, Gengyu Wang, Hammad A. Ayyubi, Kai-Wei Chang, and Shih-Fu Chang EMNLP Findings 2023 [Abs] [HTML]The field of vision-and-language (VL) understanding has made unprecedented progress with end-to-end large pre-trained VL models (VLMs). However, they still fall short in zero-shot reasoning tasks that require multi-step inferencing. To achieve this goal, previous works resort to a divide-and-conquer pipeline. In this paper, we argue that previous efforts have several inherent shortcomings: 1) They rely on domain-specific sub-question decomposing models. 2) They force models to predict the final answer even if the sub-questions or sub-answers provide insufficient information. We address these limitations via IdealGPT, a framework that iteratively decomposes VL reasoning using large language models (LLMs). Specifically, IdealGPT utilizes an LLM to generate sub-questions, a VLM to provide corresponding sub-answers, and another LLM to reason to achieve the final answer. These three modules perform the divide-and-conquer procedure iteratively until the model is confident about the final answer to the main question. We evaluate IdealGPT on multiple challenging VL reasoning tasks under a zero-shot setting. In particular, our IdealGPT outperforms the best existing GPT-4-like models by an absolute 10% on VCR and 15% on SNLI-VE. Code is available at this https URL
2022
 Weakly-Supervised Temporal Article Grounding Long Chen, Yulei Niu, Brian Chen, Xudong Lin, Guangxing Han, Christopher Thomas, Hammad Ayyubi, Heng Ji, and Shih-Fu Chang EMNLP 2022 [Abs] [HTML]
Weakly-Supervised Temporal Article Grounding Long Chen, Yulei Niu, Brian Chen, Xudong Lin, Guangxing Han, Christopher Thomas, Hammad Ayyubi, Heng Ji, and Shih-Fu Chang EMNLP 2022 [Abs] [HTML]Given a long untrimmed video and natural language queries, video grounding (VG) aims to temporally localize the semantically-aligned video segments. Almost all existing VG work holds two simple but unrealistic assumptions: 1) All query sentences can be grounded in the corresponding video. 2) All query sentences for the same video are always at the same semantic scale. Unfortunately, both assumptions make today’s VG models fail to work in practice. For example, in real-world multimodal assets (eg, news articles), most of the sentences in the article can not be grounded in their affiliated videos, and they typically have rich hierarchical relations (ie, at different semantic scales). To this end, we propose a new challenging grounding task: Weakly-Supervised temporal Article Grounding (WSAG). Specifically, given an article and a relevant video, WSAG aims to localize all “groundable” sentences to the video, and these sentences are possibly at different semantic scales. Accordingly, we collect the first WSAG dataset to facilitate this task: YouwikiHow, which borrows the inherent multi-scale descriptions in wikiHow articles and plentiful YouTube videos. In addition, we propose a simple but effective method DualMIL for WSAG, which consists of a two-level MIL loss and a single-/cross- sentence constraint loss. These training objectives are carefully designed for these relaxed assumptions. Extensive ablations have verified the effectiveness of DualMIL.
2020
 Progressive Growing of Neural Ordinary Differential Equations Hammad A. Ayyubi, Yi Yao, and Ajay Divakaran ICLR Workshop on Integration of Neural Networks and Differential Equations 2020 [Abs] [HTML]
Progressive Growing of Neural Ordinary Differential Equations Hammad A. Ayyubi, Yi Yao, and Ajay Divakaran ICLR Workshop on Integration of Neural Networks and Differential Equations 2020 [Abs] [HTML]Neural Ordinary Differential Equations (NODEs) have proven to be a powerful modeling tool for approximating (interpolation) and forecasting (extrapolation) irregularly sampled time series data. However, their performance degrades substantially when applied to real-world data, especially long-term data with complex behaviors (e.g., long-term trend across years, mid-term seasonality across months, and short-term local variation across days). To address the modeling of such complex data with different behaviors at different frequencies (time spans), we propose a novel progressive learning paradigm of NODEs for long-term time series forecasting. Specifically, following the principle of curriculum learning, we gradually increase the complexity of data and network capacity as training progresses. Our experiments with both synthetic data and real traffic data (PeMS Bay Area traffic data) show that our training methodology consistently improves the performance of vanilla NODEs by over 64%.
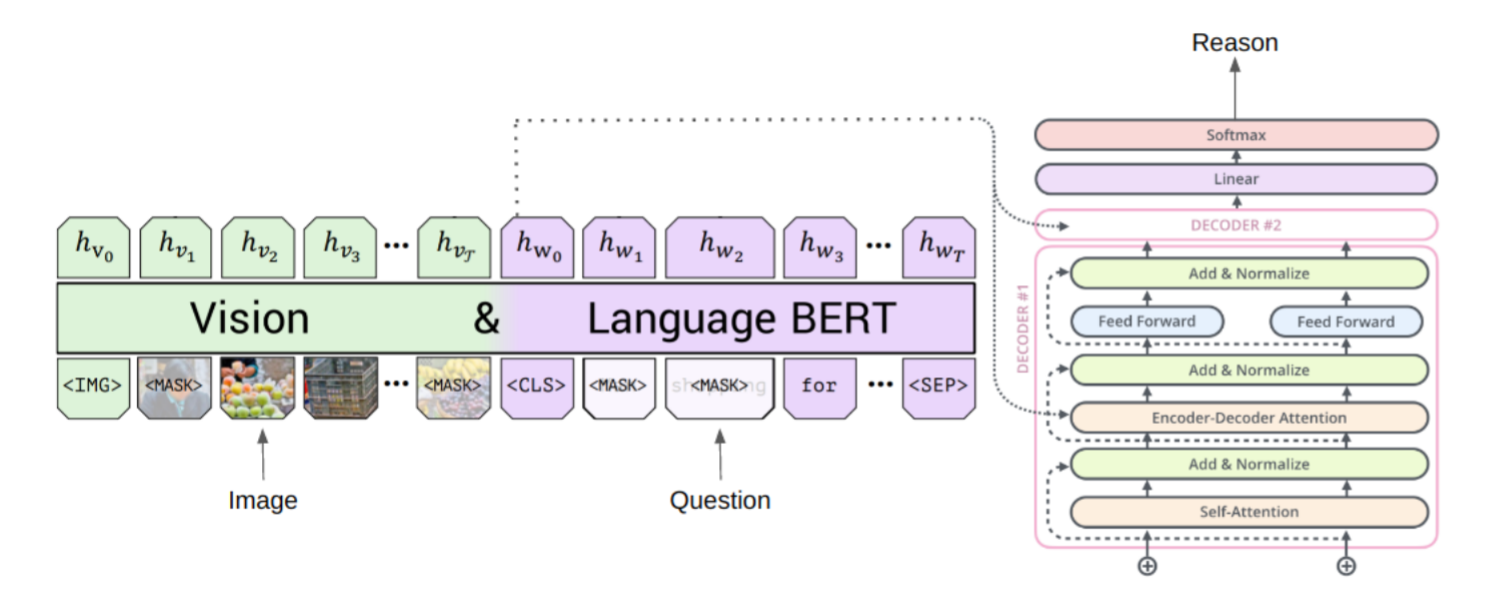 Leveraging Human Reasoning to Understand and Improve Visual Question Answering Hammad A. Ayyubi UC San Diego, MS Thesis 2020 [Abs] [HTML]
Leveraging Human Reasoning to Understand and Improve Visual Question Answering Hammad A. Ayyubi UC San Diego, MS Thesis 2020 [Abs] [HTML]Visual Question Answering (VQA) is the task of answering questions based on an image. The field has seen significant advances recently, with systems achieving high accuracy even on open-ended questions. However, a number of recent studies have shown that many of these advanced systems exploit biases in datasets, text of the question or similarity of images in the dataset. To study these reported biases, proposed approaches seek to identify areas of images or words of the questions as evidence that the model focuses on while answering questions. These mechanisms often tend to be limited as the model can answer incorrectly while focusing on the correct region of the image or vice versa. In this thesis, we seek to incorporate and leverage human reasoning to improve interpretability of these VQA models. Essentially, we train models to generate human-like language as evidence or reasons/rationales for the answers that they predict. Further, we show that this type of system has the potential to improve the accuracy on VQA task itself as well.
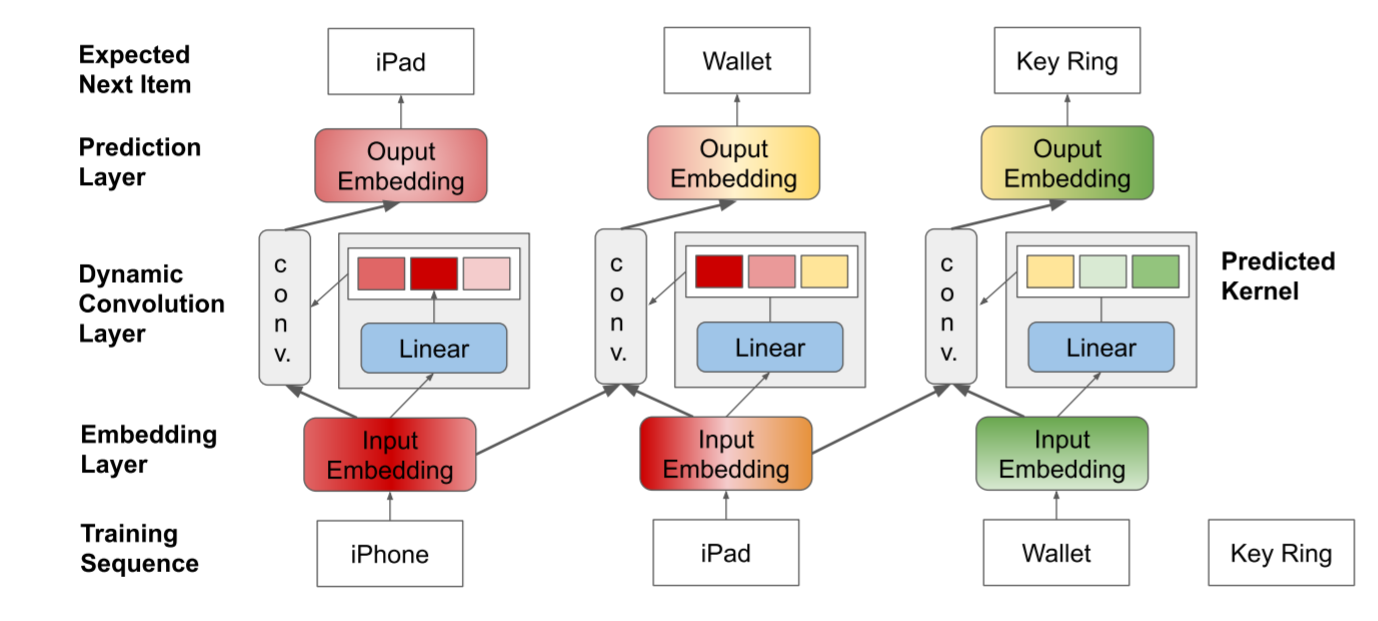 DynamicRec: A Dynamic Convolutional Network for Next Item Recommendation Md Mehrab Tanjim, Hammad A. Ayyubi, and Garrison W Cottrell Proceedings of the 29th ACM International Conference on Information and Knowledge Management 2020 [Abs] [HTML]
DynamicRec: A Dynamic Convolutional Network for Next Item Recommendation Md Mehrab Tanjim, Hammad A. Ayyubi, and Garrison W Cottrell Proceedings of the 29th ACM International Conference on Information and Knowledge Management 2020 [Abs] [HTML]Recently convolutional networks have shown significant promise for modeling sequential user interactions for recommendations. Critically, such networks rely on fixed convolutional kernels to capture sequential behavior. In this paper, we argue that all the dynamics of the item-to-item transition in session-based settings may not be observable at training time. Hence we propose DynamicRec, which uses dynamic convolutions to compute the convolutional kernels on the fly based on the current input. We show through experiments that this approach significantly outperforms existing convolutional models on real datasets in session-based settings.
2019
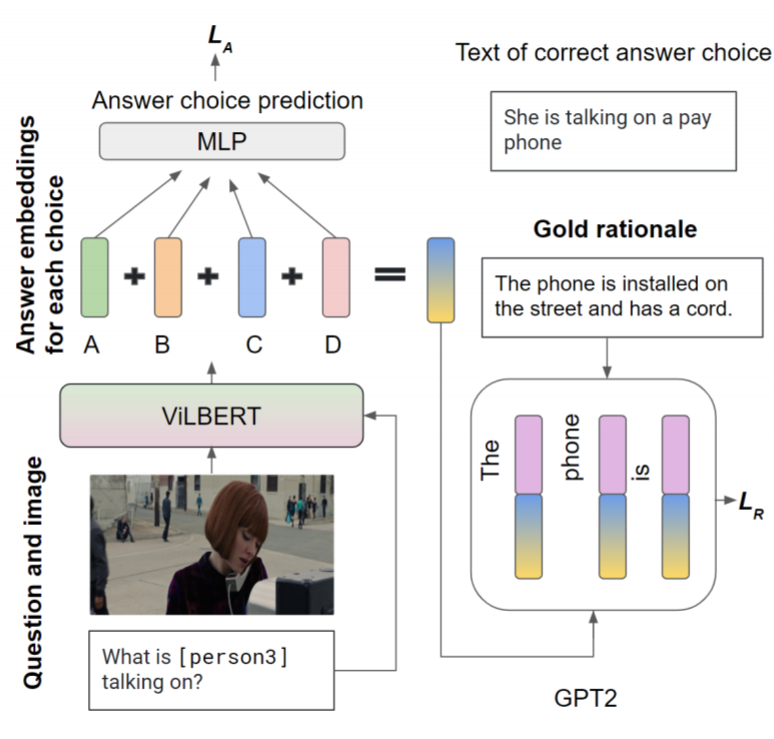 Generating Rationale in Visual Question Answering Hammad A. Ayyubi*, Md. Mehrab Tanjim*, Julian McAuley, and Garrison W. Cottrell arXiv:2004.02032 2019 [Abs] [HTML]
Generating Rationale in Visual Question Answering Hammad A. Ayyubi*, Md. Mehrab Tanjim*, Julian McAuley, and Garrison W. Cottrell arXiv:2004.02032 2019 [Abs] [HTML]Despite recent advances in Visual Question Answering (VQA), it remains a challenge to determine how much success can be attributed to sound reasoning and comprehension ability. We seek to investigate this question by proposing a new task of rationale generation. Essentially, we task a VQA model with generating rationales for the answers it predicts. We use data from the Visual Commonsense Reasoning (VCR) task, as it contains ground-truth rationales along with visual questions and answers. We first investigate commonsense understanding in one of the leading VCR models, ViLBERT, by generating rationales from pretrained weights using a state-of-the-art language model, GPT-2. Next, we seek to jointly train ViLBERT with GPT-2 in an end-to-end fashion with the dual task of predicting the answer in VQA and generating rationales. We show that this kind of training injects commonsense understanding in the VQA model through quantitative and qualitative evaluation metrics.
 GANspection Hammad A. Ayyubi arXiv:1910.09638 2019 [Abs] [HTML]
GANspection Hammad A. Ayyubi arXiv:1910.09638 2019 [Abs] [HTML]Generative Adversarial Networks (GANs) have been used extensively and quite successfully for unsupervised learning. As GANs don’t approximate an explicit probability distribution, it’s an interesting study to inspect the latent space representations learned by GANs. The current work seeks to push the boundaries of such inspection methods to further understand in more detail the manifold being learned by GANs. Various interpolation and extrapolation techniques along with vector arithmetic is used to understand the learned manifold. We show through experiments that GANs indeed learn a data probability distribution rather than memorize images/data. Further, we prove that GANs encode semantically relevant information in the learned probability distribution. The experiments have been performed on two publicly available datasets - Large Scale Scene Understanding (LSUN) and CelebA.